

So-VITS-SVC是一个开源的AI数字语音合成大模型,基于VITS(Vector-Quantized Variational Autoencoder with Multi-head Self-Attention)的开源AI人声克隆语音合成项目。同时也是2023年夏天红遍大江南北的”AI孙燕姿“背后的AI技术。
模型简介:
So-VITS-SVC 是一个开源的数字音频合成转换AI模型,由 PlayVoice 团队开发。该模型使用 SoftVC 内容编码器来提取源音频的语音特征,然后将这些特征向量直接馈入 VITS 模型,而无需将其转换为基于文本的中间表示。因此,原始音频的音调和语调得以保留。
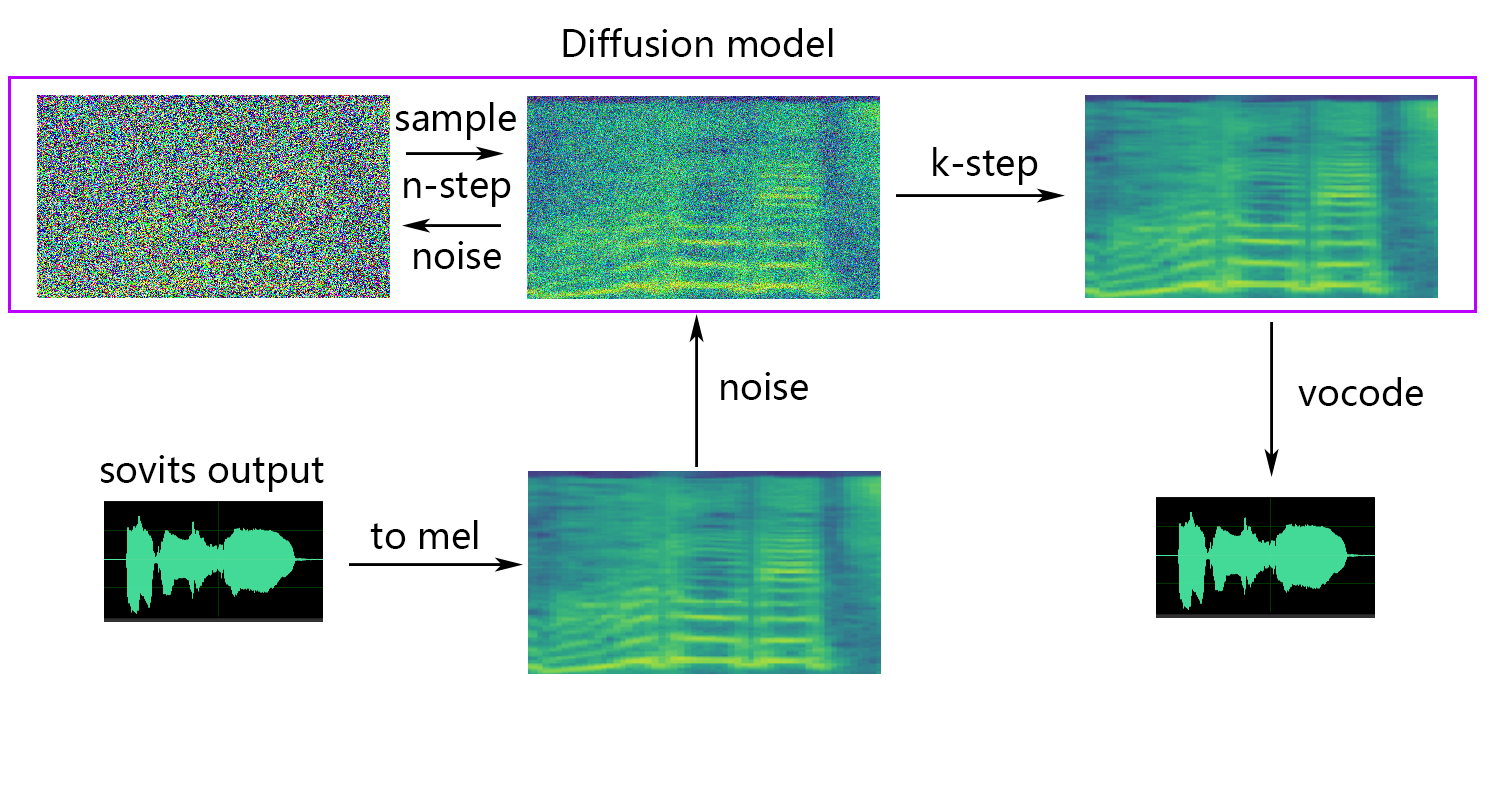
So-VITS-SVC 在声音质量、音调匹配和语调保留方面都表现出良好的效果。
- 在声音质量方面,So-VITS-SVC 生成的声音与原始声音非常接近,具有清晰的音质和自然的音色。
- 在音调匹配方面,So-VITS-SVC 能够准确地匹配目标声音的音调,从而生成具有一致音调的歌唱声音。
- 在语调保留方面,So-VITS-SVC 能够保留原始声音的语调,从而生成具有自然语气的歌唱声音。
功能:
高质量的人声合成:So-VITS-SVC模型可以生成接近原声或者原唱的人声合成音频,音质清晰,音色相似,音准准确,韵律自然,表现力丰富。可以适应不同风格和类型的歌曲,例如流行、摇滚、古风等,并且可以处理不同语言和方言的歌词。
简单易用的训练和推理:So-VITS-SVC模型提供了完整的训练和推理教程和工具包,用户只需要按照步骤进行操作,就可以在本地或者云端训练自己的音色模型,并用它来生成人声合成音频。该模型对于电脑的硬件要求并不高,只需要支持CUDA的6G显存以上的NVIDIA显卡,以及足够的硬盘空间。也提供了多种数据集预处理和切片工具,以及多种可视化和调试工具,方便用户优化和监控训练过程。
丰富多样的预训练模型:So-VITS-SVC模型目前已经提供了多种语言(中文、日文、英文等)和多种音色(碧蓝档案、初音未来、洛天依等)的预训练模型供用户下载和使用。这些预训练模型都经过了大量的数据集训练和优化,效果非常出色。用户可以直接用这些预训练模型来生成人声合成音频,也可以在这些预训练模型的基础上进行微调,以适应自己的需求。
So-VITS-SVC 可用于各种应用,例如:
- 歌唱声音转换:将一个人的声音转换为另一个人的声音,以进行歌唱。
- 歌唱声音模仿:模仿另一个人的歌唱声音。
- 歌词生成:为歌曲生成歌词。
总的来说,So-VITS-SVC是一个基于VITS的开源人声克隆项目,具有高质量的人声合成、简单易用的训练和推理、丰富多样的预训练模型等特点。其可以应用于翻唱歌曲、生成语音、语音合成等领域。
So-VITS-SVC 是一个免费的模型,可在 GitHub 上找到。

官方网址:github.com/svc-develop-team/so-vits-svc
前往官网
